Je suis un boulet...
Ou comment une mauvaise configuration de votre reverse proxy peut exclure votre site de google...


Salut !
Oui ça fait une éternité que je n’ai pas posté. La flemme et une perte de motivation. J’aime faire mes guides mais à peine terminé, il faudrait déjà en refaire la majorité vu la vitesse à laquelle tout évolue (c’est le cas par exemple de tous mes guides avec Traefik alors que ça m’a pris des heures à tout mettre à plat comme il faut). Et donc pas de post depuis plus d’un an ! Pourtant je n’ai pas chômé, j’ai continué à avancer sur tous mes dockers et je trouve qu’aujourd’hui j’ai une solution vraiment efficace et intéressante.
Mais ce n’est pas le sujet. En peaufinant mes dockers le week-end dernier, j’en ai profité pour faire un peu de ménage sur la machine virtuelle (VM) qui fait tourner mon site web. Je regarde un peu mon WordPress (le site web), quelques statistiques sous Matomo (tracking du site web) et là je me dis, tiens c’est étrange, je ne vois passer aucun crawler (les robots d’indexation de google, apple et bing). Comme ça faisait une éternité que je n’avais pas regardé (plus d’un an), je me dis que c’est peut être du à un paramètre qui a changé dans une mise à jour entre temps (je fais les mises à jour en automatique, je ne m’en occupe pas). Je vais faire un tour du côté de Clouflare et la je vois bien dans mes logs que les bots passent tous les jours. Humm. Je commence à me dire que je suis tombé sur quelque chose. Allez, soyons logique et testons les résultats de la recherche sur google tout simplement pour voir ce que ça donne. Et la, c’est le drame :
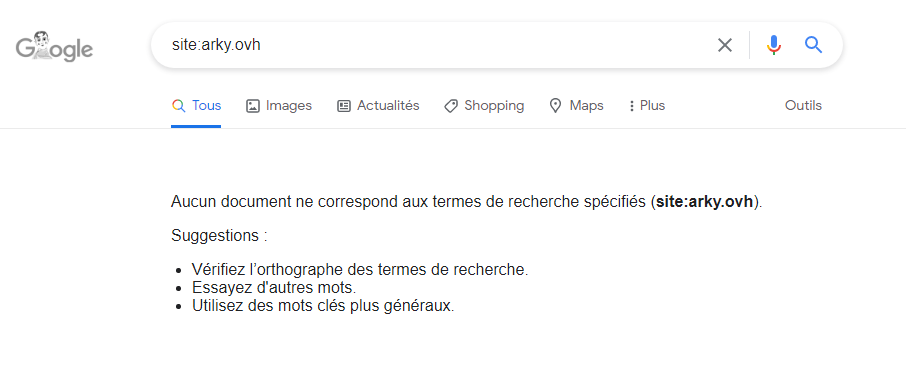
WTF !!!! Comment mon site peut-il avoir complètement disparu de Google ??? Je vais checker mes fichiers de configuration de WordPress, je vérifie les règles de pare-feu sous Cloudlare, hum non, rien de concluant. Je me lance dans des recherches sous Google, je trouve rien sauf un article concernant Google Search Console qui permet de se rendre compte de la façon dont les bots de google vous évalue. Ah, ça semble être enfin une information utile. Bon comme Google connait toute ta vie, on va dire que le setup est ultra rapide et je lance en moins de 5min le test d’indexation du site web:
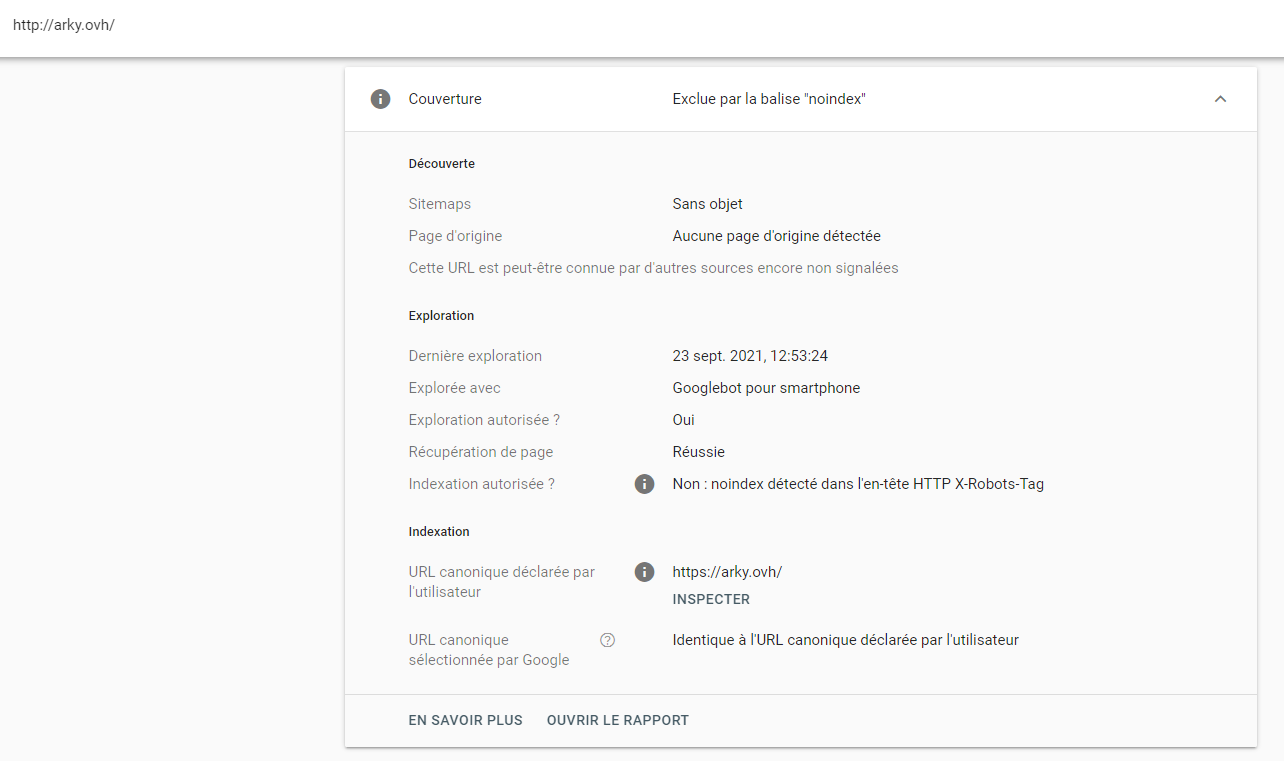
Page exclue par la balise Noindex. Euhh??? Non, ça je ne l’ai utilisé que pour certaines applications de mon NAS, pas pour mon site web… Je regarde le détail, Noindex détecté dans l’en tête HTTP X Robots Tag. Ouuuhhhh boudioou, un éclair de lumière ! Ca me dit quelque chose. Je me souviens d’avoir lu des informations sur ce paramètre quand j’ai mis en place Traefik 2 (reverse-proxy) début 2020. Je me précipite sur mes fichiers et je vois dans la configuration des middlewares (sécurité du reverse-proxy) ceci:
customResponseHeaders: X-Robots-Tag: "none,noarchive,nosnippet,notranslate,noimageindex,"
Oh mon dieu, je suis un boulet… Je me suis auto-désindexé de Google comme un grand il y a plus d’un an et je ne m’en suis même pas rendu compte… Faut dire qu’à l’époque, j’avais trouvé l’ajout de tous les paramètres de sécurité, un énorme plus comparé à la version 1 de Traefik. Sauf qu’au final j’en ai peut être un peu trop mis… Bon, virons ça, on relance le conteneur et on va checker avec notre meilleur ami Google:

C’est fou, ça marche mieux dis donc… La moralité de l’histoire, en dehors du fait que je suis un boulet? Quand on fait des modifications majeures (et c’était le cas lors du passage de Traefik 1 à 2), il faut s’assurer que les basiques soient toujours fonctionnels ! Bon bah, welcome back sur le web Arky (‘fin dans le monde de Google mais c’est presque pareil).
@+